
Instruction Set Architectures
14. Instruction Set Architectures
In this Chapter, we begin the transition of our focus from the engineering of digital systems in general to the engineering of contemporary general purpose computers, the practical embodiment of the universal Turing machines of Section 13.4. The universal TM was intended as a conceptual tool -- a thought experiment rather than a proposal for a practical implementation. In practical terms, it suffers from at least three difficulties:- Infinite hardware: an infinite tape as its main storage resource.
- Performance limitations: including bit-serial computations, long access times for distant memory locations on the tape.
- Programming model: An unconstrained string of 1s and 0s on a tape provide a poor programming interface for building and maintaining large, modular software systems.
Steps toward a General Purpose Computer
14.1. Steps toward a General Purpose Computer
We naturally tend to view algorithms for practical computations as sequences of operations: each algorithm is a recipe outlining a series of sequential steps to be followed.Datapath vs. Control Circuitry
14.1.1. Datapath vs. Control Circuitry
Generalizing Datapath Design
14.1.2. Generalizing Datapath Design
The ad-hoc datapaths sketched in the above example could be generalized to allow a modestly wider range of computations to be implemented by modifying the logic of the control FSM.von Neumann Architecture
14.2. von Neumann Architecture
The multi-purpose architectures of the 1940s fail the test for Turing universality of Section 13.4.1, for at least two simple reasons:- A finite bound on the size of their control logic, hence on the complexity of the "program" to be executed;
- A finite bound on the amount of data that can be stored during the course of their computation.
- a Central Processing Unit or CPU, comprising logic that performs actual computation;
- a Main Memory used to store both data and coded instructions that constitute a program for processing that data; and
- an Input/Output component for communicating inputs and results with the outside world.
The Stored-Program Computer
14.2.1. The Stored-Program Computer
The use of a single memory subsystem to store both programs and data, inspired by the tape of the Universal Turing Machine, constitutes a major difference between von Neumann's proposal and prior special-purpose computers whose computational function was wired into their circuitry.Anatomy of a von Neumann Computer
14.2.2. Anatomy of a von Neumann Computer
CPU Datapath
14.2.2.1. CPU Datapath
The datapath portion of the CPU typically includes some modest amount of internal storage, often in the form of a set of general-purpose registers each capable of holding a word of data.CPU Control
14.2.2.2. CPU Control
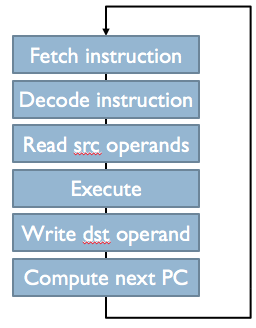
Control Fetch/Execute loop
Instruction Set Architecture as an Abstraction
14.3. Instruction Set Architecture as an Abstraction
Before diving into the detailed specification of our example stored-program instruction set, it is worth reflecting on the design of an instruction set architecture or ISA as an engineering problem. An instruction set architecture specifies how programs are to be encoded for a family of computers sharing that architecture. Once coded in a specific ISA, a program can generally be run on various machines sharing that ISA provided sufficient memory and I/O resources are available. In this respect, an ISA is an important engineering abstraction: it specifies an interface between hardware and software, and -- like other engineering abstractions -- allows both technologies to evolve independently. The design of an instruction set is subject to a number of pressures:- Cost/performance. It is clearly desireable that an ISA be cheap to implement and execute programs quickly.
- Cost/performance scaling. A related, more subtle goal is that the ISA be consistent with implementations over a wide range of the cost/performance spectrum; that is, allowing specific programs to be run quickly on expensive computers or more slowly on cheaper ones.
- Model of computation. During much of the history of general-purpose computing, an ISA design often reflected a particular language family or computation model: machines were designed around, say, ALGOL or LISP.
- Backward compatibility. Common ISA desiderata include the requirement that a new architecture be able to run dusty deck software written for now-obsolescent machines.
- Future compatibility. Forward-looking ISAs are designed to anticipate new trends in both hardware and software, often by providing an evolutionary path for the ISA itself.
The Beta: An Example Instruction Set Architecture
14.4. The Beta: An Example Instruction Set Architecture
To facilitate concrete examples throughout the remainder of this course, we introduce a simple but representative instruction set architecture called the Beta (a name inspired by the Alpha architecture of the now-defunct Digital Equipment Corporation). The Beta's ISA and programming model will be described in remaining sections of this Chapter and Chapter 16; two different implementations will be the subjects of Chapter 18 and Chapter 20. The Beta ISA is a representative 32-bit RISC design, and lends itself to implementation strategies similar to that sketched in Section 14.2.2. The programmer-visible state of the CPU is stored in a set of general-purpose registers and a program counter.Beta CPU State
14.4.1. Beta CPU State
Byte Addressing
14.4.2. Byte Addressing
Endian Battles
14.4.2.1. Endian Battles
The advent of byte addressing stimulated a famous and costly battle within the computer industry, dubbed the Endian battle in a tongue-in-cheek article by Danny Cohen. The issue arises on machines that allow both individual bytes and 32-bit words to be addressed within the same memory. The 32-bit word stored at location 0 comprises four bytes, whose addresses are 0, 1, 2, and 3; but which portion of the 32-bit word addressed as byte 0? There are two obvious answers to this question: byte 0 is the high-order byte of the 32-bit word, or its the low-order byte. Although in retrospect the industry could have done fine using either convention, manufacturers split quite evenly between the two options: DEC and Intel, for example, used the little endian (byte 0 is low order) convention, while IBM and Motorola chose the opposite big endian byte order (until IBM chose to use Intel processors in its PC product line). This lack of standardization of byte ordering extends beyond ISA design to representation of multi-byte data in shared data structures and network communications, complicating interface specifications and communication. While proponents of each byte ordering convention once defended their choice with religious zeal, it is generally recognized today that, aside from backwards compatibility issues, the advantages of either choice are outweighed by the costs of inconsistency among the industry.Notation: Register Transfer Language
14.5. Notation: Register Transfer Language
In order to describe sequences of computation steps in a relatively ISA-independent way, e.g. for documenting the semantics of individual instructions, we use an informal register transfer language (RTL).R0 ← Mem[0x100] tmp ← R0 + 3 Mem[104] ← tmp | 0x7
Programming Conventions: Storage Use
14.6. Programming Conventions: Storage Use
The design of an instruction set architecture reflects, to a great extent, the set of programming conventions it is intended to support. Modern programming involves a basic set of common constructs such as variables, expressions, procedures, and loops that need to be supported efficiently.int x, y; y = x * 37;
- For every variable, we assign a location in main memory to hold a representation of its current value.
- Instructions operate on operands in general registers, which are used to hold for short-term copies of variable and other temporary values.
- Computations involving variables requires (1) loading the variable values from main memory into registers, (2) performing the computation using values in registers, and then (3) storing results back into the main memory locations assigned to effected variables.
R0 ← Mem[0x1008] R0 ← R0 * 37 Mem[100C] ← R0
Instruction Coding
14.7. Instruction Coding
A major portion of an Instruction Set Architecture specification deals with the repertoire of instructions provided by compliant machines, and details of their encoding as binary contents of locations in main memory. An understanding of the representation of instructions and their interpretation by the machine constitutes the programming model presented by the machine: a specification of the machine language that constitutes the most basic hardware/software interface presented by that machine. Approaches to coding of machine instructions are subject to the engineering pressures mentioned in Section 14.3, and have evolved with hardware and software technologies over the history of the von Neumann architecture. Aspects of this evolution include- Complexity: Certain historically successful instruction sets -- including the IBM 360 and DEC VAX -- offer a rich repertoire of high-level instructions to perform relatively complex computations within a single instruction. As an example, the VAX has a single instruction whose execution evaluates an arbitrary single-variable polynomial for a given value of its variable. Such complex instruction sets -- derisively called CISC in contrast to the simpler RISC approach popularized in the 1980s -- typically demanded a simpler machine language (called microcode) hidden within the hardware that interprets the complex machine language advertised by the ISA. RISC ISAs, like the Beta, offer a limited set of basic operations as single instructions, depending on sequences of such instructions to perform more complex computations.
- Instruction size: A related issue is the number of bits used to encode a single instruction. Many CISC ISAs have variable-length instructions, allowing simple operations to be performed by short instructions (e.g. one or 2 bytes of memory) intermixed with longer instructions encoding elaborate computations. While this feature offers flexibility to encode a wide variety of operations as single instructions, it complicates instruction fetch and decoding, making certain performance improvements (such as the pipelined execution of Chapter 20) impractical. The Beta ISA takes the typical RISC route of using a single 32-bit word to encode each instruction.
- Access to main memory: Some ISAs support enconding of single instructions that perform operations (like addition) of operands stored in main memory, which requires somehow encoding their main memory locations within the instruction itself. Others, like the Beta, restrict such operations to operands in CPU registers, and provide separate instructions to move data between registers and main memory.
- Access to constants: Common computations often involve constants: you need $\pi$ to compute the area of a circle from its diameter, and 6 to compute to compute the number of ounces in a sixpack. Given that an ISA needs the ability to access the value of variables stored in main memory, constants might simply be implemented as variables that are initialized to the appropriate value and never changed. But this approach involves time and program size costs for every use of a constant; consequently, instruction sets commonly provide a simple way of embedding short instruction-stream constants directly in certain instructions to avoid the overhead of additional memory accesses. The Beta provides instructions containing short (16-bit) constants.
Beta Instructions
14.8. Beta Instructions
As suggested by the previous sections, the Beta ISA offers three general classes of instructions:- Operate class instructions: encode an ALU operation to be performed on operands held in general registers within the CPU.
- Memory access instructions: Load CPU registers from and store registers to locations within main memory.
- Flow control instructions: By default, the Beta program counter is incremented (by 4, due to byte addressing) after each instruction is fetched; hence its default operation is to execute a sequence of instructions stored at successively increasing word addresses in main memory. The flow control insructions allow this sequential execution default to be varied; they change, perhaps conditionally, the contents of the program counter and hence the next instruction to be executed. They provide for programmed loops, branches, conditional execution, and procedure calls.
- OPCODE: bits 26 through 31 of every Beta instruction. The value stored in this 6-bit field dictates what operation is encoded by the instruction, including which of the three instruction classes it represents and which of the two formats are used for the remaining bits of the instruction.
- Rc: bits 21-25 of every Beta instruction. This 5-bit field encodes the "name" of a register (meaning a number from 0 through 31 identifying one of the 32 CPU registers). It is used to encode a destination register for an operation, i.e., which register is to receive the result computed by that instruction.
- Ra: bits 16-20 of every Beta instruction. This 5-bit field encodes another register, typically the register containing a source operand to be used as an input to the operation performed by the instruction.
- Rb: bits 11-15 of Beta instructions using the first instruction format. This 5-bit field encodes another register, typically containing a second source operand.
- literal: bits 0-15 of Beta instructions using the second instruction format. This 16-bit field replaces the Rb field of the first format, and holds a 16-bit instruction-stream constant. Among other uses, it provides for operations (like ADD) in which one operation is a small constant.
Encoding Binary Operations
14.8.1. Encoding Binary Operations
The largest class of instructions in the Beta ISA are those that perform actual computation: binary arithmetic, comparisons, and bitwise logical operations on data stored in CPU registers. In a typical Beta CPU, these operations are performed in an Arithmetic Logic Unit (ALU) that takes two 32-bit binary operands as input, along with a function code specifying the operation to be performed, and produces a single 32-bit binary result. Using our first instruction format, we can encode an operation by choosing an appropriate opcode (which identifies the operation as well as the instruction format), and filling the three register-name fields to specify two source and one destination registers.Notation: Symbolic Instructions
14.8.2. Notation: Symbolic Instructions
It is convenient to have a textual symbolic representation for machine instructions; we use the notation ADD(R1,R2,R3) to designate the Beta instruction encoded with the ADD opcode, and 1, 2 and 3 in the respective fields $r_c$, $r_a$, and $r_b$. As elaborated in Section 15.2, this representation is an example of the assembly language we will use as the lowest-level programming interface to Beta processors. We might document the semantics of the ADD instruction by associating the symbolic representation of its encoding with an RTL description of the resulting execution:Beta Operate Instructions
14.8.3. Beta Operate Instructions
There is a modest repertoire of binary arithmetic and logical operations that neatly fit the same pattern as the ADD instruction. Each of these has a corresponding operate-class Beta instruction, with its unique opcode. These instructions are summarized below:| Operate Class: | ||||
|---|---|---|---|---|
 | ||||
| OP | Opcode | op | Description | |
|---|---|---|---|---|
| ADD | 100000 | + | Twos-complement addition | |
| SUB | 100001 | - | Twos-complement subtraction | |
| MUL | 100010 | * | Twos-complement multiplication | |
| DIV | 100011 | / | Twos-complement division | |
| CMPEQ | 100100 | == | equals | |
| CMPLT | 100101 | < | less than | |
| CMPLE | 100110 | <= | less than or equals | |
| AND | 101000 | & | bitwise AND | |
| OR | 101001 | | | bitwise OR | |
| XOR | 101010 | ^ | bitwise XOR | |
| XNOR | 101011 | ˜^ | bitwise XNOR | |
| SHL | 101100 | << | Shift left | |
| SHR | 101101 | >> | Shift right | |
| SRA | 101111 | >> | Shift right arithmetic (signed) |
- ADD(Rx, R31, Ry) adds the (zero) contents of R31 to Rx, storing the result in Ry. It effectivly copies the value from Rx to Ry.
- ADD(Rx, Ry, Rx) increments the value in Rx by the value in Ry. It is important to note that the source operands get the values in the registers prior to the execution of the instruction, not (in this case) the updated value being stored back into Rx.
- ADD(Rx, Rx, Ry) doubles the value in Rx, storing the result in Ry.
- ADD(Rx, Ry, R31) computes the sum of its two source operands, but stores the result in the always-zero R31 -- effectively discarding the result. This is an example of a no-operation (or NOP) instruction, whose execution has no visible effect on the CPU state beyond incrementing the PC.
32-bit Arithmetic and Overflow
14.8.3.1. 32-bit Arithmetic and Overflow
The Beta ISA includes the four basic arithmetic operations, each of which takes 32-bit operands from the source registers and returns a 32-bit result in the destination register. It is worth noting that the addition or subtraction of 32-bit values may yield a 33-bit result, incapable of fitting into the 32-bit destination register; these operations store the low-order 32 bits of the sum, discarding the high-order bit. We view arithmetic operations whose results are truncated to the low-order 32 bits as examples of arithmetic overflow, an error condition that must be considered by software. It is noteworthy that overflow of an ADD operation occurs when both source operands have the same sign (high-order bit) but the result has the opposite sign. Similarly, the result of a 32-bit multiplication can return a 32-bit result; the Beta MUL instruction returns only the low-order 32-bits of the product. Again, the circumspect programmer is responsible for avoiding or dealing with errors due to such overflow. Arithmetic overflow can be managed in a variety of ways. Among these is using more sophisticated number representations, e.g. fixed-size floating-point representations (which eliminates many overflow possibilities at the cost of numeric precision) or varible-length (or bignum) representations which require more sophisticated storage management and arithmetic implementations. While such representations can be implemented in software on the Beta, the instruction set provides direct support only for basic 32-bit arithmetic.Comparisons and Boolean Values
14.8.3.2. Comparisons and Boolean Values
Operate class instuctions on the Beta include three comparison operations -- CMPEQ, CMPLT, and CMPLE, that operate on two signed binary source operands and return a Boolean (true/false) result in the destination register. The output of these instructions is a single bit in the low-order position of the result: true is represented by a binary 1, while false is represented by 0. These Boolean results may be used in subsequent conditional branch instructions to effect the flow of control, e.g. for implementing conditional execution of blocks of code, loops, and recursion; we'll see examples shortly.Logical and Arithmetic Shifts
14.8.3.3. Logical and Arithmetic Shifts
The logical shift operations of the Beta, SHL(Ra,Rb,Rc) and SHR(Ra,Rb,Rc) produce a result in Rc which is the contents of Ra shifted left or right by a number of bit positions given by the low-order 5 bits of Rb; vacated bit positions in the result are filled with zero. Such shifts have many uses -- among them, the multiplication or rough division of binary integers by powers of two. If R1 contains a positive integer $N$ and R2 contains 5, for example, executing SHL(R1, R2, R3) leaves the value $2^5 \cdot N$ in R3. Again, this operation is subject to possible overflow, whence the result will be the low-order 32 bits of the product $2^5 \cdot N$. Similarly, shifting a positive integer $N$ right by 5 bits using SHR yields the integer portion of $N / 2^5$. If $N$ is a negative integer, however, the result will not reflect this division by a power of two: zeros shifted into high order bits will render a positive output word. To support scaling of signed quantities by right shifting, the Beta provides an additional instruction SRA which behaves like SHR with the exception that vacated bit positions are filled with the sign bit of the original Ra contents.Operate Instructions with Constants
14.8.4. Operate Instructions with Constants
To support operations involving constants, the Beta ISA supports variants of each of the above instructions in which the second source operand is a 16-bit signed constant embedded directly in the instruction itself. The symbolic names of these instuctions are the names of the corresponding operate class instruction with an appended "C" -- indicating that the Rb field has been replaced by a literal constant operand. The format of these instructions allows only 16 bits for the representation of the constant. To support negative as well as positive embedded constants, this 16-bit field is sign-extended to yield a signed 32-bit value which is used as the second source operand. Sign extension simply involves replication of the sign bit of the embedded constant -- bit 15 -- to synthesize the high-order 16 bits of the 32-bit source operand.| Operate Class with Constant: | ||||
|---|---|---|---|---|
 | ||||
| OPC | Opcode | op | Description | |
|---|---|---|---|---|
| ADDC | 110000 | + | Twos-complement addition | |
| SUBC | 110001 | - | Twos-complement subtraction | |
| MULC | 110010 | * | Twos-complement multiplication | |
| DIVC | 110011 | / | Twos-complement division | |
| CMPEQC | 110100 | == | equals | |
| CMPLTC | 110101 | < | less than | |
| CMPLEC | 110110 | <= | less than or equals | |
| ANDC | 111000 | & | bitwise AND | |
| ORC | 111001 | | | bitwise OR | |
| XORC | 111010 | ^ | bitwise XOR | |
| XNORC | 111011 | ˜^ | bitwise XNOR | |
| SHLC | 111100 | << | Shift left | |
| SHRC | 111101 | >> | Shift right | |
| SRAC | 111111 | >> | Shift right arithmetic (signed) |
- ADDC(R31, C, Rx) adds zero to the sign-extended literal and stores it in Rx; it provides a convenient way to initialize the value in a register to a small constant.
- XORC(Rx, -1, Ry) flips all 32 bits of the value in Rx, by XORing it with a word of 32 1s. This is a convenient way to compute the bitwise complement of a binary word.
- SHLC(Rx, 5, Ry) multiplies the value in Rx by $2^5 = 32$, so long as overflow is avoided.
- ANDC(Rx, 0xFFF, Ry) zeros all but the low-order 12 bits of Rx, using the 12-bit mask 0xFFF. This is a useful step in extracting selected bits from a binary word.
Flow Control Instructions
14.8.5. Flow Control Instructions
Since by default the new value of the PC after execution of an instruction is PC+4, by default the Beta executes sequences of instructions stored at consecutively increasing word locations. Flow control instructions allow us to vary this default by storing alternative values into the PC. The Beta has three such instructions: a simple unconditional jump instruction which allows an arbitary address to be computed and loaded into the PC; and two conditional branches that allow such a jump to happen only if a computed value is zero or nonzero. As each of these instructions may load a new value into the PC, the old value in the PC may be lost as a result of their execution. While this information loss often causes no problems, the Beta flow control instructions provide a mechanism for optionally preserving the old PC value in a specified destination register. We will find this mechanism useful when we discuss procedure calls in Chapter 16. When saving the prior PC value is unnecessary, we simply specify R31 as the destination register in jumps and branches.| Flow Control: | ||||
|---|---|---|---|---|
 | ||||
| Jump: opcode 011011 | ||||
PC ← Ra |
||||
| Branch on Equal to zero: opcode 011100 | ||||
if Reg[Ra] == 0 then PC ← PC + 4 + 4*SEXT(C) else PC ← PC+4 |
||||
| Branch on Not Equal to zero: opcode 011101 | ||||
if Reg[Ra] != 0 then PC ← PC + 4 + 4*SEXT(C) else PC ← PC+4 |
||||
- If the constent field of a branch instruction contains zero, the branch target is the instruction immediately following the branch instruction itself.
- If the constent field of a branch instruction contains -1, the branch target that branch instruction itself. Such an instruction constitutes a "tight loop", whose only action is to transfer control back to itself.
- BEQ(R31, label, R31) effects an unconditional branch since the contents of R31 are always zero.
- Although rarely necessary, Beta flow control instructions provide a way for programs to access the value in the program counter as data. For example, a branch instruction whose constant field contains 0 and which specifies R0 as the destination register Rc will have the effect of loading into R0 the address of the instruction following the branch.
Memory Access Instructions
14.8.6. Memory Access Instructions
The most basic requirement for access to main memory are instructions that can read the contents of a given main memory address into a register, and write the contents of some register into a specified location in main memory. In such a minimalist approach, a register would be used to pass the main memory address in read or write instructions. That address could be the result of some arbitrary computation, so the minimalist approach is completely general. However, most ISAs provide some address computation mechanism to reduce the extra instructions needed for memory addressing. The mechanism reflects, to a great extent, software conventions for the organization of data in main memory. Common memory access patterns that have different addressing requirements include- Statically-allocated: address is a constant.
- indirect addressing: the address to be accessed is stored in another program variable.
- Array element: an access Array[i] to one of a number of elements stored in consecutive main memory locations. In this case the address of the accessed location is the sum of a base address and a computed offset.
- Record element: an access like Employee.age involving an address computed as a fixed offset from a variable record address (a pointer to the record).
- PC-relative addressing, useful for access to constant data local to the code being executed.
| Memory Access: | ||||
|---|---|---|---|---|
|
| ||||
| Load from Memory: opcode 011000 | ||||
PC ← PC+4 |
||||
| Store to Memory: opcode 011001 | ||||
PC ← PC+4 |
||||
| Load Relative: opcode 011111 | ||||
PC ← PC+4 |
||||
- LD(Ra, 0, Rc) or ST(Rc, 0, Ra) access the location whose address is in Ra.
- LD(R31, C, Rc) or ST(Rc, C, R31) access the location whose address C, so long as C fits within 15 bits. This is useful for accessing fixed locations in low memory.
Opcode assignments
14.8.7. Opcode assignments
The 6-bit Opcodes that uniquely identify each Beta instruction are shown in the table below: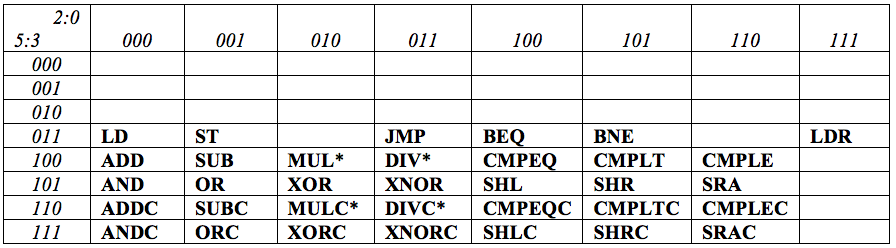 Although actual opcode assignments are generally uninteresting to the
programmer and
may be assigned arbitrarily, they are often grouped
by instruction type or on some other logical basis.
There may be implementation advantages to certain
features of the assignments; for example, the fact that
the functionally similar BEQ and BNE
opcodes differ by a single bit may make it convenient
to share the mechanism that interprets and executes them.
Although actual opcode assignments are generally uninteresting to the
programmer and
may be assigned arbitrarily, they are often grouped
by instruction type or on some other logical basis.
There may be implementation advantages to certain
features of the assignments; for example, the fact that
the functionally similar BEQ and BNE
opcodes differ by a single bit may make it convenient
to share the mechanism that interprets and executes them.
Unused Opcodes
14.8.7.1. Unused Opcodes
Note that many of the possible 6-bit opcodes are unspecified in the table: they constitute unused opcodes (UUOs) whose function has not been specified in the ISA. The UUOs may be viewed as reserved for future expansion: subsequent versions of the Beta ISA might assign opcodes, for example, to floating-point operations or instructions for accessing individual bytes of main memory. Alternatively, the UUOs may serve to allow some degree of implementation-specific customization of the instruction set. A manufacturer of signal-processing equipment might, for example, extend the Beta with application-specific instructions for a custom processor used in her products. Even users of off-the-shelf stock Beta processors may extend the instruction set by software (via mechanism to be discussed shortly). While these alternative perspectives regarding UUOs -- and others -- are legitimate, there are tensions among them. To the extent that the ISA establishes a standard for the Beta, use of unspecified or functionally ambiguous aspects undermines the guarantee that software written to that ISA will run on hardware that implements the ISA. A user who writes software for a customised Beta ISA forgoes compatibility with existing Betas, although her software might run alongside existing software on an extended Beta. Two users building on mutually incompatibile ISA extensions guarantee that their software will never run on the same processor. History has shown that careful thinking about major abstractions like the design of an ISA is a worthwhile engineering investment. An ISA that aspires to transcend several generations of hardware technology, for example, needs to provide an evolutionary path for the hardware/software interface. An ISA designed to support multiple implementations reflecting a variety of cost/performance tradeoffs might provide alternative implementation approaches to certain functions. For example, an ISA might specify floating-point instructions that are implemented in (slow) software in cheap CPUs and in (faster) hardware in higher-end processors. Each processor in this spectrum can execute the same software, albeit at varying speeds and cost.Handling UUOs
14.8.7.2. Handling UUOs
Recognising that certain opcodes are unused in our ISA raises a subtle question: should the ISA specifiy the behavior of the Beta when it encounters an instruction containing one of these illegal opcodes? And if so, what behavior is desirable? There are a number advantages to the careful handling of UUOs (and other error conditions that may arise) and the complete specification this handling in the ISA. A key capability is the ability for an error to invoke a software handler, whose execution somehow deals with the error. The handler might simply give a coherent error message. More ambitious handlers might perform a divide operation in software, masking the fact that the current Beta does not provide hardware support for the DIV instruction.Exception Handling
14.9. Exception Handling
Handling of UUOs motivates the remaining aspect of our ISA specification: dealing with various computational events that are extraneous to the normal steps in instruction execution. We use the term exceptions to describe this class of events, which fall into three categories:- Faults represent error conditions that arise as a result of executing an instruction. Examples include illegal opcode errors arising from attempts to execute instructions having unimplemented opcodes, out-of-bounds-access faults resulting from access to a main memory location beyond the range of addresses available on the machine, or a divide-by-zero fault resulting from a division by a zero denominator.
- Traps are similar to faults, but are the intended consequence of instruction execution. For example, a UUO whose execution invokes a handler that emulates an unsupported hardware instruction may provide a measure of software compatibility at low cost.
- External Interupts are events generated by external stimuli, such as input/output devices. Examples include a keyboard interrupt that signals the fact that a key has been struck, or a network interrupt that signals the arrival of a packet of network traffic.
Invoking a handler
14.9.1. Invoking a handler
The key mechanism required for processing exceptions is the ability to specify, for each exception type, a handler to be run when that exception occurs. A handler is simply a Beta program, stored as a sequence of Beta instructions in some region of main memory, whose execution is triggered by the computational event associated with the exception. Each type of exception interrupts the execution of the currently running program, temporarily "borrowing" the CPU to run the handler code to deal with the exception. In the case of traps and external interrupts, the handler returns control to the interrupted program, which continues executing from the point at which it was interrupted. The invocation of a handler simply requires loading the Beta's PC with the starting address of that handler, and executing instructions from there. However, there are several closely related characteristics we require from our mechanism for exception processing:- Information preserving: The state of the interrupted program must be preserved (so it can be restarted), and accessible to the handler code (for error diagnosis or instruction set extension);
- Transparency: It must be possible to interrupt an arbitrary program, and return to that program without effecting its subsequent execution. The interrupt is thus invisible to the interrupted program.
- One of the Beta's general registers, R30, is dedicated to use by exception processing. We memorialize this dedication by renaming it XP, for eXception Pointer.
- XP is not to be used for ordinary programming, e.g.applications.
- Each type of exception is assigned a unique address in main memory for an interrupt vector, a single Beta instruction that branches to the handler for that exception.
- An exception of type $e$ is processed by the two step sequence:
XP ← PC+4where $IVector_e$ is the interrupt vector address assigned for exceptions of type $e$.
PC ←$IVector_e$
- To maintatin transparency, interrupt handlers must save all CPU state (e.g. contents of registers) and restore it prior to returning to the interrupted program.
- Since the value in XP is the address of the instruction
following the interrupted instruction, a handler for an
external interrupt will typically return to the interrupted program
via a sequence like
SUBC(XP, 4, XP) JMP(XP)
Kernel Mode
14.9.2. Kernel Mode
In the Beta, interrupt handlers are part of the operating system kernel, a body of code permanently installed in a region of main memory that is a topic of the final module of this course. Typically the operating system kernel is priviledged, in that it may directly access I/O devices and other basic system resources that unpriviledged programs, such as applications, access only via requests to the operating system. For this reason, it is common to maintain a bit of CPU state that distinguishes whether the CPU is currently executing priviledged OS code -- eg an interrupt handler -- or unpriviledged user code.Reentrance
14.9.3. Reentrance
Although some systems allow the execution of exception handlers themselves to be interruped by exceptions, such reentrant handler execution presents some new difficulties. Since we have allocated the single register XP to hold the address of the interrupted program, for example, what happens if the handler is interrupted before it is able to save XP elsewhere? Such problems are solvable, but at some cost in complexity. As a result, handler reentrance is often avoided rather than being supported. A simple way to avoid reentrant interrupts is to make the processor only take exceptions while in user mode. This requires that the operating system kernel be carefully written, both to avoid errors (which may not be properly handled) and to avoid depending on trapped instructions for functional extensions. The Beta follows this route. Errors and traps are best avoided in kernel mode code, and attention to external interrupt requests from I/O devices is deferred until the CPU is running in user mode. This implies that the Beta will turn a deaf ear to I/O devices while in kernal mode, and must return occasionally to user mode to process external interrupt requests. The impact of these constraints on operating system structure will be explored in the next module of this course.Factorial in Software
14.10. Factorial in Software
The Beta ISA introduced in later sections of this chapter provide minimalist but representative support for contenporary programming practices. Subsequent chapters will provide many substantive examples, illustrating typical software conventions for application and operating system programming.
N: (input value)
...
// Compute Fact(N), leave in R0:
Fact: ADDC(R31, 1, R0) // R0 <- 1
LD(R31, N, R1) // load N into R1
loop: MUL(R0, R1, R0) // R0 = R0 * R1
SUBC(R1, 1, R1) // R1 = R1 - 1
BNE(R1, loop, R31)// if R1 != 0, branch
// HERE with R0 = Fact(N)
References
14.11. References
- Beta ISA reference
- Single-sheet Beta summary, a useful cheat-sheet to have around when working Beta-related problems.
Further Reading
14.12. Further Reading
- von Neumann, John, First Draft Report on the EDVAC (1945). Incomplete draft by von Neumann detailing what became known as the von Neumann architecture.
- Hennessy, John L., and Patterson, David A., Computer Architecture: A Quantitative Approach, Fifth Edition, Elsevier 1012. Leading contemporary text on computer architecture, by the two best-known proponents of the RISC movement.
- Cohen, Danny, "On Holy Wars and a Plea for Peace", 1980.